Data MiningThis description gives more detail than was provided in Investing Process about how data mining is used to develop high-return strategies. The normal scientific process is to postulate a hypothesis and then attempt to disprove the null hypothesis on the logical basis that if it can’t be not true, it must be true. Rather than starting from a hypothesis or set of logical screen criteria that are then back-tested, data mining is a statistical tool that explores thousands of possible statistical relationships that predict the dependent variable. Instead of testing something that would seem possible, data mining finds the relationships first and then leaves it to the explorer to try to make sense of these relationships. While it is nice to have reasons for what works, and certainly makes it easier to sell a strategy to a client, it really doesn’t matter to me why something works if I have reason to think it will work in the future. The research process is to first formulate the data to be imported into KnowledgeSEEKER, which is the data mining tool that I use. In the example and illustration which follows, I have selected the annual return rate for the next month as the dependent variable which I’m trying to predict. In addition I have to find, import and clean the data for the other variables which I think might predict or explain the dependent variable. Most of my data is imported from Stock Investor Pro, a data source from the American Association of Investors (www.AAII.com) with about 1,500 data elements each week on about 8,000 stocks. I usually eliminate stocks priced less than one dollar and trading fewer than 5,000 shares daily. I also limit the extreme returns, as such outliers distort the averages. (Usually the top and bottom 1%, which comes to about +-1,000%.) My data source is limited to stocks which currently exist, meaning that in a study of ten years, my results will be distorted by not having data on stocks that disappeared because of acquisition or extinction. KnowledgeSEEKER (KS) produces results in a decision-tree, rather than as a neural network which is another form of data mining. The level of required statistical significance is usually set at .01, meaning that the relationship has to happen less than 1 time in 100 by chance. With a large number of rows, such as in the example below, significance is usually more than six digits. The tree shown in the example below is from the research I did when trying to find out the longer-term returns for low-priced stocks. The top cell says that the average return each month was .5%, the standard deviation was 20% and there were 747,814 records in the analysis. These were the selected aggregation of each month’s returns for ten years. The program divides each of the variables into ten roughly equal-sized clusters, in this case about 75,000, and then searches to see if adjacent clusters have a similar predictability in explaining the dependent variable, in this case monthly return. If the results are similar, it combines the cells. It then sorts the variables in the order of significant predictive value. As is typical, date is the most predictive, but since we can’t screen by what the market will do for a specific time period, I have chosen price as the top cluster to show you. The 0.0 means that the findings are significant beyond .0000001. The F value and Degrees of Freedom are statistical measures. The price breaks above the rows of cells are where it breaks in getting the ten roughly equal-sized clusters. If you look at the average returns by price, you can see that stocks between $.64 and $18.51 had returns above .7% each month, with stocks below that level and above $25.71 being negative. Stocks between $9.76 and $13.67 have the best returns at 1% each month. Within that cluster, the New York Stock Exchange (N) had returns of 1.8% each month and a standard deviation two-thirds that of the NASDAQ (M). This is remarkable because the higher returns have the effect of raising the standard deviation. Within this cluster, returns are thus more than three times normal, and 60% as volatile. Nice. Within the 25,032 stocks of this cluster, we see that the best returns are for April, at an average of 4.6%. However, there were only ten Aprils in this study, not enough to have much statistical meaning. You can also see the poor returns for the third quarter over the last ten years for this particular profile. By pointing and clicking, one can explore all of the variables that are statistically predictive under any one cell. One can search for the positive results to include, or the negative results to exclude (or go short, which I haven’t done). I spend hours exploring these relationships on one computer, and log the results into an outline in a spreadsheet on an adjacent computer. As with any research, preparing the data is a major part of the task. KnowledgeSEEKER Decision Tree Example (Ten Years of Monthly Market Data) 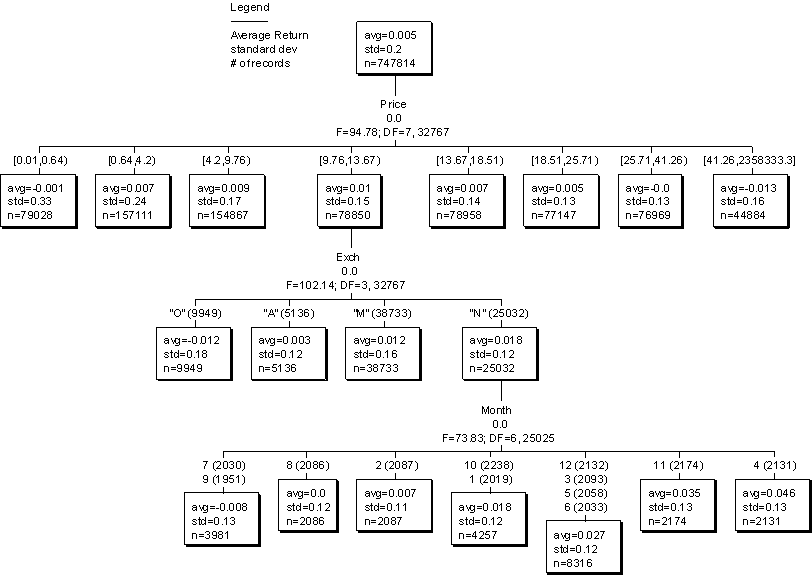
My experience from data mining is that the rules for successful screens change with a major shift in the market such as occurred on 3/03, 4/04, or 8/04. Data mining works well to identify a momentum and get on board until such changes occur. I have not found a way to use it to predict the timing of reversals. My response to date has been to mix the time frames, such as researching weekly returns within the framework of ten year monthly results. Back to Papers |

